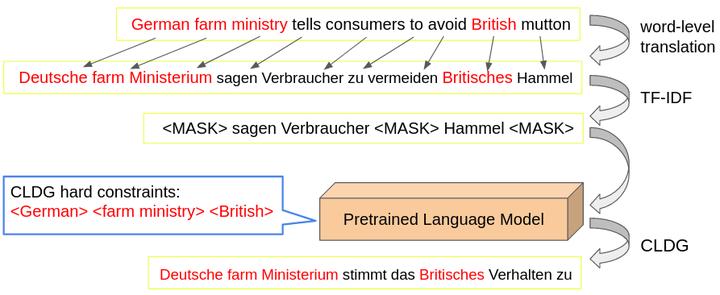
 Illustration of our data generation pipeline.
Illustration of our data generation pipeline.
Abstract
Named Entity Recognition (NER) in low-resource languages has been a long-standing challenge in NLP. Recent work has shown great progress in two directions: developing cross-lingual features/models to transfer knowledge to low-resource languages, and translating source-language training data into low-resource target-language training data by projecting annotations with cheap resources. We focus on the second direction in this study. Existing methods suffer from the low quality of the resulting annotated data in the target language; for example, they cannot handle word order and lexical ambiguity well. To handle these limitations we propose a novel approach that uses the projected annotation to generate pseudo supervised data with a transformer language model and a constrained beam search. This allows us to generate more diverse, higher quality, as well as higher quantities of annotated data in the target language. Experiments demonstrate that, when combining our method with available cross-lingual features, it achieves state-of-the-art or competitive performance on NER in a low-resource setting, especially for languages that are distant from our source language, English.